
In 2025, we take for granted that a single click can trigger insights from petabytes of data scattered across continents, but rewind just three decades, and moving data from one system to another was a nightly ritual that could bring entire IT departments to their knees. Data wasn’t always the lifeblood of business, it had to earn that status, drop by painstaking drop.
At the heart of this transformation lies ETL: Extract, Transform, Load. Born in the era of mainframes and data warehouses, ETL was the unsung workhorse that made business intelligence possible. It took raw data from disparate sources, cleaned and restructured it, then delivered it to centralized repositories where analysts could finally make sense of it all. What started as overnight batch jobs running on premises has evolved into sophisticated, cloud-native pipelines processing millions of events per second.
This evolution wasn’t just technological, it was philosophical. Each decade brought new challenges that forced data engineers to rethink fundamental assumptions about how data should move, when it should transform, and where it should live. From the rigid batch windows of the 1990s to today’s streaming architectures, the lessons learned along the way have shaped not just our tools, but our entire approach to data architecture.
In this post, we’ll trace ETL’s journey through four decades of innovation, examining how each era’s constraints drove creativity, and how yesterday’s breakthroughs became today’s best practices. Because understanding where ETL has been is essential to navigating where it’s going next.
The Origins of ETL (1980s – 1990s)
The 1980s brought a critical realization: operational databases built for daily transactions couldn’t answer strategic business questions without grinding to a halt. This sparked the data warehouse revolution, purpose-built repositories where data from across the organization could be consolidated for analysis. Pioneers like Bill Inmon and Ralph Kimball established foundational architectures, while relational databases from Oracle, IBM, and Teradata became the backbone of analytical computing, but warehouses didn’t populate themselves.
ETL emerged as the essential mechanism to extract data from operational systems, transform it through business rules, and load it into these central repositories. Tools like Informatica PowerCenter and IBM DataStage provided visual development environments, but everything ran on-premise during precious “batch windows”, those few hours between midnight and 6 AM when nightly jobs could process without impacting business operations.
The model worked, but it didn’t scale gracefully. As data volumes grew, batch windows became dangerously tight, and transformations tightly coupled to specific systems became brittle and difficult to maintain. Any schema change could require weeks of rework, turning ETL developers into bottlenecks managing fragile webs of dependencies. Infrastructure costs were punishing, every new data source demanded more servers, storage, and licensing fees, and there was always a ceiling on how big those boxes could get.
The lesson was clear, centralization created immense value, enabling organizations to see across silos and make data-driven decisions for the first time, but rigidity was the price, tightly coupled architectures and inflexible batch processes struggled to adapt as fast as business needs evolved, setting the stage for the next wave of innovation.
The Growth Era: ETL in the Early 2000s
The early 2000s marked ETL’s evolution from niche tool to mission-critical infrastructure. Informatica, IBM DataStage, and Talend dominated with graphical interfaces that promised to democratize data integration.
By the mid-2000s, ETL consumed a big chunk of typical BI project budgets, cementing its role as both foundation and bottleneck. The promise was seductive: build comprehensive workflows once, report indefinitely.
Reality proved messier. Development cycles stretched from weeks to months. Complex workflows became unmaintainable labyrinths. Version control was an afterthought, and pipeline failures were often silent or cryptic, leaving teams scrambling to diagnose issues across dozens of interconnected jobs.
The lesson was sobering: organizations that treated ETL as “just plumbing” paid the price in data quality incidents and unreliable dashboards. Success required treating ETL with production-grade rigor, comprehensive testing, monitoring, and documentation weren’t optional but survival necessities when business decisions depended on trustworthy data.
The Big Data Revolution (2010s)
The 2010s shattered assumptions about data scale. During this decade, the rapid growth of Big Data technologies redefined how information was stored, processed, and moved across organizations, laying the foundation for today’s cloud-native, AI-driven data ecosystems.
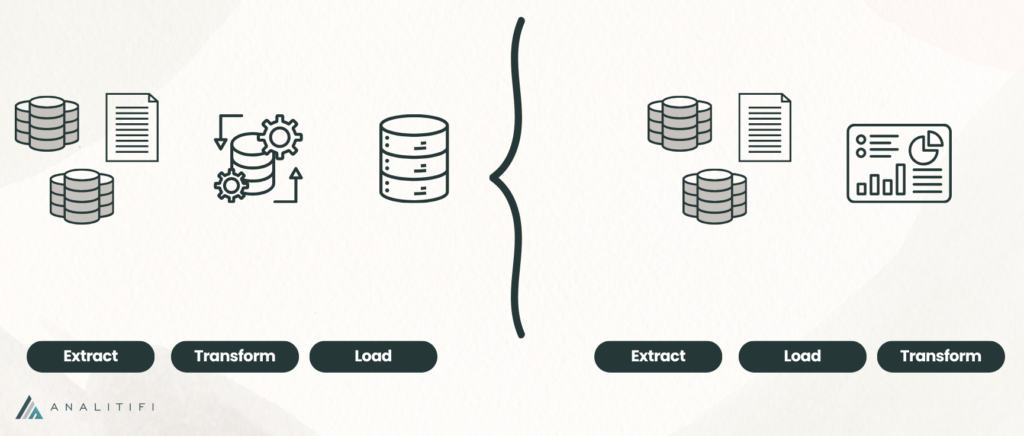
The shift from ETL to ELT emerged as cloud data warehouses such as Snowflake, Redshift, and BigQuery demonstrated their ability to transform data directly within the warehouse at massive scale. These platforms proved that separating compute from storage allowed for flexible, elastic scalability that legacy systems couldn’t match. Meanwhile, Hadoop and Spark made distributed data processing accessible to organizations of all sizes, showing that large-scale performance could be achieved with clusters of standard hardware.
Streaming also became a fundamental part of modern data architecture. As platforms like Apache Kafka gained widespread adoption, organizations began to treat real-time data processing as a core capability rather than an advanced feature. Batch processing became optional, and the expectation shifted toward immediate insights and continuous data movement across systems.
The lesson was transformative: tight coupling between compute and storage was the constraint holding everything back. Cloud warehouses scaled them independently. Hadoop proved commodity hardware could outperform expensive infrastructure. Kafka showed data could flow continuously, enabling millisecond reactions instead of overnight batches.
The 2010s taught that flexibility and scalability were complementary, achieved through distribution, separation of concerns, and elastic cloud economics. Organizations could suddenly handle petabytes where they’d previously struggled with terabytes.
The Modern Era: Data Pipelines in the Cloud (2020s)
Throughout the 2020s, the modern data stack reshaped the data landscape, introducing specialized and interoperable tools that expanded what teams could achieve with data. The 2025 merger of Fivetran and dbt Labs represented a major milestone in that ongoing evolution, bringing together a company with $600 million in ARR, more than 10,000 customers, and a shared vision for the future of data integration and transformation.
The philosophy was straightforward yet transformative, using best-of-breed tools for specific tasks, all connected through standardized interfaces. Tools like Fivetran and Airbyte streamlined data ingestion with ready-made connectors, while dbt brought software engineering practices such as version control and testing into SQL-based transformations. Airflow, meanwhile, enabled teams to orchestrate complex workflows through code, creating a unified and automated data pipeline ecosystem.
Infrastructure-as-code became default, pipelines versioned in Git, tested in CI/CD, and deployed automatically. The promise was organizational agility: swap components, experiment, and scale pieces independently.
The 2020s brought a deeper shift in focus, data reliability became a central concern. As organizations increasingly relied on data to drive decisions, ensuring trust in that data became just as important as collecting or transforming it. This gave rise to the field of data observability, emphasizing visibility into data quality, lineage, and system health. At the same time, DataOps platforms gained traction as teams sought to apply DevOps principles to data workflows, automating processes and improving collaboration between engineering and analytics teams.
Data lineage, anomaly detection, and comprehensive observability became requirements, not nice-to-haves. The lesson was clear: automation, modularity, and visibility were interdependent necessities. Automated pipelines without observability were silent time bombs. Modular architectures without orchestration became tangled. Visibility without automation meant drowning in alerts. Success required production-grade rigor, monitoring, testing, ownership, and planning for inevitable failures.
Beyond ETL: The Future of Data Movement
The future of data movement is being written in real time. IDC predicted that by 2025, 90% of the world’s largest 1,000 companies (the Global 1000, or G1000) would leverage real-time intelligence to improve outcomes such as customer experience through event-streaming technologies. Leading innovators are already ahead, LinkedIn processes trillions of daily events through Kafka, and Netflix uses event sourcing to deliver personalized experiences to over 260 million subscribers.
The shift to event-driven architectures fundamentally reimagines data flow. APIs become event publishers, not just endpoints. Change data capture happens in microseconds, not batch windows. Systems react to now, not last night. AI-powered tools automate data cleaning, transformation, and anomaly detection, with ML models identifying patterns to improve quality. Data pipelines are expected to grow 3-4x by decade’s end, driven by AI/ML workloads demanding self-optimizing architectures.
Meanwhile, the concept of data mesh began challenging traditional centralized data architectures. It promotes a decentralized model where individual domains own and manage their own data, treating it as a product that serves others across the organization. This approach encourages autonomy, accountability, and scalability but also introduces significant organizational and governance challenges. Adopting a data mesh requires cultural transformation and strong federated governance, areas where many enterprises are still developing maturity.
Data pipelines must evolve with organizational complexity. Rigid, centralized architectures that worked for small teams can’t scale to hundreds of autonomous domain experts. Manual tuning that handled gigabytes chokes on petabytes. Batch processes can’t serve real-time demands.
Success will belong to organizations embracing architectural flexibility, supporting batch and streaming, centralized and decentralized, human-tuned and AI-optimized approaches, adapting to each problem rather than forcing everything through the same pipeline.
Conclusion
Four decades after the first nightly batch jobs crawled through mainframe data, ETL remains as essential as ever, but it would be unrecognizable to those early pioneers. The journey from rigid batch windows to real-time event streams, from monolithic platforms to composable modern stacks, from manual tuning to AI-driven optimization hasn’t rendered ETL obsolete. Instead, it’s revealed a deeper truth: the fundamental challenge of moving, transforming, and delivering data reliably never goes away. It just takes new forms as our ambitions grow.
The organizations that thrived through each era weren’t those that clung to yesterday’s patterns or chased every new trend indiscriminately. They were the ones that learned the hard lessons, that centralization without flexibility becomes rigidity, that speed without governance breeds chaos, that scalability requires decoupling, that automation without observability is blind faith, and carried those lessons forward while embracing new capabilities.
Looking ahead, the next chapter is already being written. As data pipelines grow three to four times larger by decade’s end and AI workloads reshape what we ask of our infrastructure, the pipelines themselves must become more intelligent. They’ll need to self-optimize, self-heal, and adapt to patterns humans can’t see. They’ll need to serve both the real-time demands of operational systems and the analytical depths of strategic intelligence. They’ll need to balance centralized governance with decentralized ownership, supporting both the simplicity small teams need and the sophistication enterprises demand.
The question isn’t whether ETL will evolve, history assures us it will. The question is whether our organizations can evolve with it, learning from each era’s hard-won wisdom while remaining bold enough to reimagine what data movement could become. As data becomes more intelligent, so must our pipelines. The next four decades start now.
Modernize Your Data Infrastructure with Analitifi
Understanding ETL’s evolution is one thing. Building pipelines that embody its hard-won lessons is another entirely. It requires expertise spanning legacy systems and cutting-edge architectures, governance frameworks and event-driven patterns, enterprise scalability and startup agility. That’s where the right partner makes all the difference.
At Analitifi, we specialize in designing data infrastructure that learns from the past while embracing the future. We don’t just migrate your ETL jobs to the cloud, we architect modern data platforms tailored to your organization’s maturity, complexity, and growth trajectory. Our approach starts with understanding your current pain points and strategic data needs, then builds modular, observable, and scalable solutions that evolve with your business rather than constraining it.
Whether you’re struggling with brittle legacy pipelines that break with every schema change, drowning in data quality issues you can’t diagnose, or ready to embrace real-time architectures but uncertain where to start, we can help. Let’s transform your data movement from a maintenance burden into a competitive advantage, reliable, observable, and ready for whatever the next decade brings.
If you’re interested in how ETL has evolved, and what that means for modern data teams, you might enjoy diving deeper into the foundations that make today’s pipelines possible.
Check out “Building a Robust Data Infrastructure: Key Considerations” for a closer look at the architectural choices behind scalable systems, or explore “Future-Proof Data Strategy: Key Steps for Long-Term Success” to see how organizations can align their pipelines with long-term business goals.
Ready to build data pipelines for the modern era?
Contact Analitifi today to schedule a FREE consultation and discover how we can modernize your data infrastructure while preserving everything that works.